
EKS Auto Mode でサクッと機械学習用インスタンスを利用してみる。 AWS 独自設計チップ搭載の Trainium と Inferentia を使ってみた!
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。枡川です。
re:Invent 2024 で Auto Mode が登場したことで、EKS を利用するケースは以前より多くなるのではないかと思っています!
特に GPU 利用したい場合は、小規模な利用でも ECS on EC2 より EKS Auto Mode の方が楽に感じる方も多いのではないでしょうか?
Kubernetes と ECS、それぞれへの習熟度合いに寄りますが、基盤となる EC2 の管理を AWS 側が実行してくれるというのは極めて魅力的です。
Fargate の今後の GPU 対応次第とはなりますが、2024 年 12 月時点では EKS Auto Mode が GPU が必要なコンテナアプリケーションを実行する際のファーストチョイスになりうるのでは...?と思っています。
NVIDIA 製の GPU チップも EKS Auto Mode で楽に利用できるようですが、今回は EKS Auto Mode で AWS 独自設計チップを搭載したコスパ抜群の機会学習専用インスタンスである Trainium と Inferentia を扱ってみようと思います!
NVIDIA 製 GPU も下記記事で試してみました。
EKS Auto Mode だと GPU/Neuron インスタンス利用はどう楽になる?
まず、ワークロードを配置する EC2 の作成、削除、パッチ適用は EKS 側の責務と明言されていることが大きなメリットです。
利用者側は Pod の再配置が行われることを意識する必要がありますが、EC2 へのセキュリティパッチ適用等は考える必要がありません。
Amazon EKS Auto Mode is responsible for creating, deleting, and patching EC2 Instances. You are responsible for the containers and pods deployed on the instance.
https://docs.aws.amazon.com/eks/latest/userguide/automode-learn-instances.html
また、Auto Mode を利用するだけで GPU 利用がサポートされるとも記載があります。
EKS Auto Mode enables the following Kubernetes capabilities in your EKS cluster:
Compute auto scaling and management
Application load balancing management
Pod and service networking and network policies
Cluster DNS and GPU support
Block storage volume support
https://aws.amazon.com/jp/blogs/aws/streamline-kubernetes-cluster-management-with-new-amazon-eks-auto-mode/?trk=d57158fd-77e3-423f-9e1e-005fd2a64d89&sc_channel=el
元々、2024/10 のアップデートによって AL2023 ベースの GPU タイプの EKS 最適化 AMI が利用できるようになっています。
この AMI には GPU を利用するために必要なドライバーがプリセットされており、追加のインストール作業が不要となります。
EKS Auto Mode も同等の AMI を利用するので、追加のドライバーインストールが不要です。
EKS 最適化 NVIDIA AMI には NVIDIA ドライバー、NVIDIA Fabric Manager、NVIDIA コンテナツールキットが含まれ、EKS 最適化 Neuron AMI には Neuron ドライバーが含まれています。
https://aws.amazon.com/jp/about-aws/whats-new/2024/10/amazon-eks-nvidia-aws-neuron-instance-types-al2023/
このアップデートにより、Neuron インスタンスの利用も楽になっております。
また、非 Auto Mode の EKS ではコンテナからブロックボリュームを扱うためには EBS CSI driver をセットアップする必要がありましたが、Auto Mode はセットアップ不要で利用できるようになっています。
EFS を利用したい場合はアドオンの追加が必要なので、ご注意下さい。
さらに、マネージドな形で Karpenter が組み込まれていることも大きなメリットです。
Karpenter はコンテナ起動に必要なノードが足りなくなった際に直接 AWS API をコールして EC2 を用意するという特徴があり、Auto Scaling ベースより速いスケールアウトが可能です(以前非 GPU のコンテナで試した際は 50 秒程度でした)。
また、NodePool と呼ばれる EC2 のグループを複数扱えるため、一つのクラスターで利用目的に依って CPU ベースのノードと GPU(Neuron) ベースのノードを使い分ける際に便利です。
EKS Auto Mode で Trainium を扱う
では、さっそく試してみます。
今回は EKS Workshop をベースに進めますが、元々 Auto Mode ベースのシナリオにはなっているわけではないため、一部修正しつつ進めていきます。
また、Trainium インスタンスが ap-northeast-1 に対応していなかったので、us-east-1 を利用します。
EKS クラスターの作成手順は省略しますので、必要に応じて下記記事をご参照下さい。
eksctl で作成したパターン。
Terraform で作成したパターン。
v1.31 で Auto Mode の EKS を作成して、ノードが存在しない状態からスタートです。
% kubectl get node
No resources found
まず、NodePool を作成します。
組み込みの NodePool では CPU しか利用できないため、独自の NodePool を作成する必要があります。
組み込みの NodePool とユーザー定義の NodePool については別途記事を記載したので、ご興味があれば読んでいただけると幸いです。
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: aiml
spec:
template:
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand", "spot"]
- key: eks.amazonaws.com/instance-family
operator: In
values: ["inf2", "trn1"]
nodeClassRef:
group: eks.amazonaws.com
kind: NodeClass
name: default
EKS Workshop では非 Auto Mode でセルフマネージドの Karpenter をセットアップしているのですが、spec.requirements のキーが微妙に変わっています(karpenter.k8s.aws/instance-family → eks.amazonaws.com/instance-family)。
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: aiml
spec:
template:
metadata:
labels:
instanceType: "neuron"
provisionerType: "karpenter"
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- on-demand
- key: karpenter.k8s.aws/instance-family
operator: In
values:
- inf2
- trn1
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: aiml
manifests/modules/aiml/inferentia/nodepool/nodepool.yaml
Auto Mode を扱うにあたりハマりやすいポイントだと思うので、ご注意下さい。
この状態ではまだ箱を作っただけなので、EKS ノードはプロビジョニングされていません。
% kubectl get node
No resources found
コンテナイメージは deep-learning-containers に公開されているものを利用します。
まず、名前空間を作成します。
apiVersion: v1
kind: Namespace
metadata:
name: aiml
Service Account を作成します。
apiVersion: v1
kind: ServiceAccount
metadata:
name: inference
namespace: aiml
また、 Pod Identity を利用して成果物を S3 に出力する権限を Pod に付与しました。

こちらの詳細手順についても省略しますが、実際に試す際は下記記事をご参照下さい。
トレーニング用のコンテナを作成します。
apiVersion: v1
kind: Pod
metadata:
labels:
role: compiler
name: compiler
namespace: aiml
spec:
nodeSelector:
karpenter.sh/nodepool: aiml
eks.amazonaws.com/instance-family: trn1
eks.amazonaws.com/instance-size: 2xlarge
containers:
- command:
- sh
- -c
- sleep infinity
image: 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04
name: compiler
resources:
limits:
aws.amazon.com/neuron: 1
serviceAccountName: inference
作成直跡に下記のような Warning がでますが、Neuron インスタンスのセットアップに時間が掛かっているだけなのでしばらく待ちます。
Warning FailedCreatePodSandBox 3m42s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "c2ddb4b44955263cd3a9b1a5ff5917239bfb1e36f8a4d26b6d87d9980374202a": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: Error received from AddNetwork gRPC call: rpc error: code = Unavailable desc = connection error
EKS Workshop では 10 分程度かかる可能性があると記載されていましたが、5 分程度で利用できるようになっていました。
% kubectl describe pod -n aiml
Name: compiler
Namespace: aiml
Priority: 0
Service Account: inference
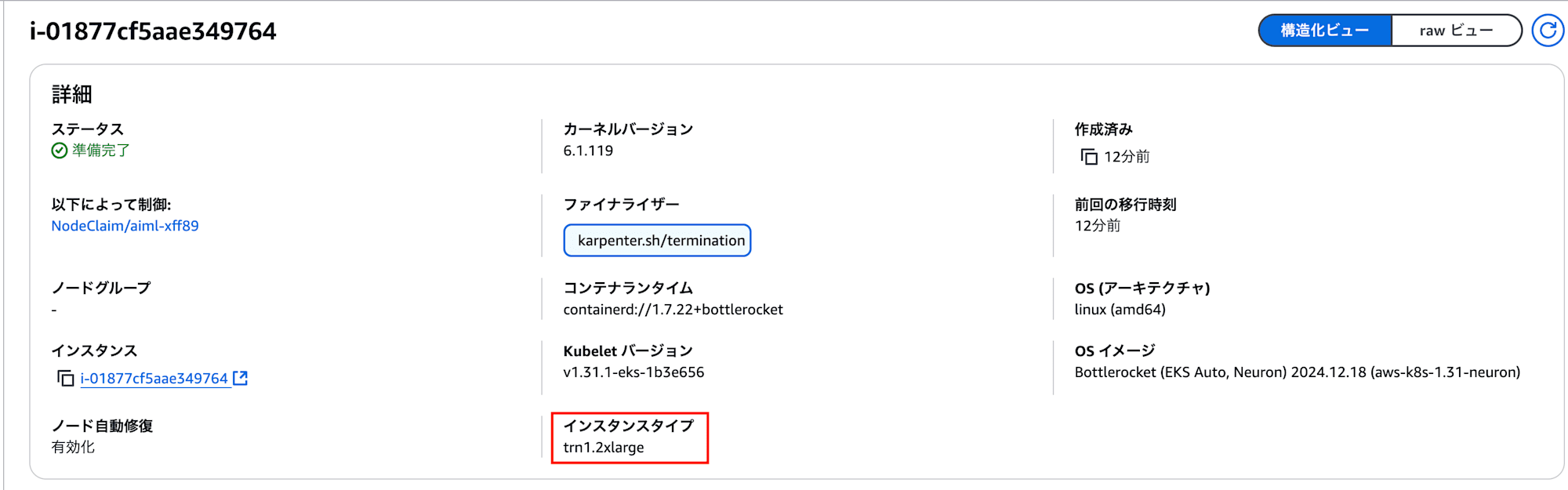
Node: i-01877cf5aae349764/10.0.100.204
Start Time: Wed, 01 Jan 2025 23:21:56 +0900
Labels: role=compiler
Annotations: <none>
Status: Running
IP: 10.0.100.48
IPs:
IP: 10.0.100.48
Containers:
compiler:
Container ID: containerd://662a05429c97052779bc13bfa21573c1570eca944893ebd816b75bf44361a335
Image: 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04
Image ID: 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training-neuronx@sha256:5a7c49b548c7f43e5bccbd3b367d4ff3aaa27b4a64a28a36d72855dd67f59609
Port: <none>
Host Port: <none>
Command:
sh
-c
sleep infinity
State: Running
Started: Wed, 01 Jan 2025 23:26:01 +0900
Ready: True
Restart Count: 0
Limits:
aws.amazon.com/neuron: 1
Requests:
aws.amazon.com/neuron: 1
Environment:
AWS_STS_REGIONAL_ENDPOINTS: regional
AWS_DEFAULT_REGION: us-east-1
AWS_REGION: us-east-1
AWS_CONTAINER_CREDENTIALS_FULL_URI: http://169.254.170.23/v1/credentials
AWS_CONTAINER_AUTHORIZATION_TOKEN_FILE: /var/run/secrets/pods.eks.amazonaws.com/serviceaccount/eks-pod-identity-token
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-7cb8h (ro)
/var/run/secrets/pods.eks.amazonaws.com/serviceaccount from eks-pod-identity-token (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
eks-pod-identity-token:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 86400
kube-api-access-7cb8h:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: eks.amazonaws.com/instance-family=trn1
eks.amazonaws.com/instance-size=2xlarge
karpenter.sh/nodepool=aiml
Tolerations: aws.amazon.com/neuron:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Nominated 9m28s karpenter Pod should schedule on: nodeclaim/aiml-xff89
Warning FailedScheduling 9m13s (x5 over 9m29s) default-scheduler no nodes available to schedule pods
Normal Scheduled 9m3s default-scheduler Successfully assigned aiml/compiler to i-01877cf5aae349764
Warning FailedCreatePodSandBox 9m3s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "c2ddb4b44955263cd3a9b1a5ff5917239bfb1e36f8a4d26b6d87d9980374202a": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: Error received from AddNetwork gRPC call: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing: dial tcp 127.0.0.1:50051: connect: connection refused"
Normal Pulling 8m49s kubelet Pulling image "763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04"
Normal Pulled 4m59s kubelet Successfully pulled image "763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04" in 3m49.784s (3m49.784s including waiting). Image size: 16556630013 bytes.
Normal Created 4m59s kubelet Created container compiler
Normal Started 4m59s kubelet Started container compiler
マネジメントコンソールから確認しても trn1 のインスタンスが用意されてますね!
コンテナが用意されたのでトレーニングに進みます。
とはいえ、今回はあくまで Trainium を使ってみることが趣旨なので、トレーニング用のデータは追加しません。
事前学習されたモデルをそのまま利用します。
import torch
import numpy as np
import os
import torch_neuronx
from torchvision import models
image = torch.zeros([1, 3, 224, 224], dtype=torch.float32)
## Load a pretrained ResNet50 model
model = models.resnet50(pretrained=True)
## Tell the model we are using it for evaluation (not training)
model.eval()
model_neuron = torch_neuronx.trace(model, image)
## Export to saved model
model_neuron.save("resnet50_neuron.pt")
manifests/modules/aiml/inferentia/compiler/trace.py
EKS Workshop のファイルをそのまま利用した所、書き方が古いと Warning が表示されたので、一応 (pretrained=True を weights=models.ResNet50_Weights.DEFAULT に変更しておきます。
/usr/local/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/local/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
PyTorch の公式ドキュメント を参考に、model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT) と指定しました。
import torch
import numpy as np
import os
import torch_neuronx
from torchvision import models
image = torch.zeros([1, 3, 224, 224], dtype=torch.float32)
## Load a pretrained ResNet50 model
model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
## Tell the model we are using it for evaluation (not training)
model.eval()
model_neuron = torch_neuronx.trace(model, image)
## Export to saved model
model_neuron.save("resnet50_neuron.pt")
ファイルをコンテナ内にコピーします。
kubectl cp -n aiml ./trace.py compiler:/
スクリプトを実行します。
% kubectl -n aiml exec compiler -- python /trace.py
Downloading: "https://download.pytorch.org/models/resnet50-11ad3fa6.pth" to /root/.cache/torch/hub/checkpoints/resnet50-11ad3fa6.pth
100%|██████████| 97.8M/97.8M [00:00<00:00, 361MB/s]
.
Compiler status PASS
無事完了したので、出力されたモデルを S3 バケットにアップロードします。
% kubectl -n aiml exec compiler -- aws s3 cp ./resnet50_neuron.pt s3://${BUCKET_NAME}/
upload: ./resnet50_neuron.pt to s3://<BUCKET_NAME>/resnet50_neuron.pt
EKS Auto Mode で Inferentia を扱う
出力されたモデルを利用して推論に進みます。
ここでは、推論用チップを搭載した Inferentia を利用します。
今回もコンテナイメージは deep-learning-containers に公開されているものを利用します。
NodePool は先ほど作成したものを使いつつ、inf2 インスタンスをリクエストします。
apiVersion: v1
kind: Pod
metadata:
name: inference
namespace: aiml
labels:
role: inference
spec:
nodeSelector:
karpenter.sh/nodepool: aiml
eks.amazonaws.com/instance-family: inf2
eks.amazonaws.com/instance-size: xlarge
containers:
- command:
- sh
- -c
- sleep infinity
image: 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-inference-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04
name: inference
resources:
limits:
aws.amazon.com/neuron: 1
serviceAccountName: inference
今回は 6 分程度で利用可能になりました。
理由までは不明ですが、EKS Workshop 記載の時間の半分くらいでした。
% kubectl describe pod -n aiml
Name: inference
Namespace: aiml
Priority: 0
Service Account: inference
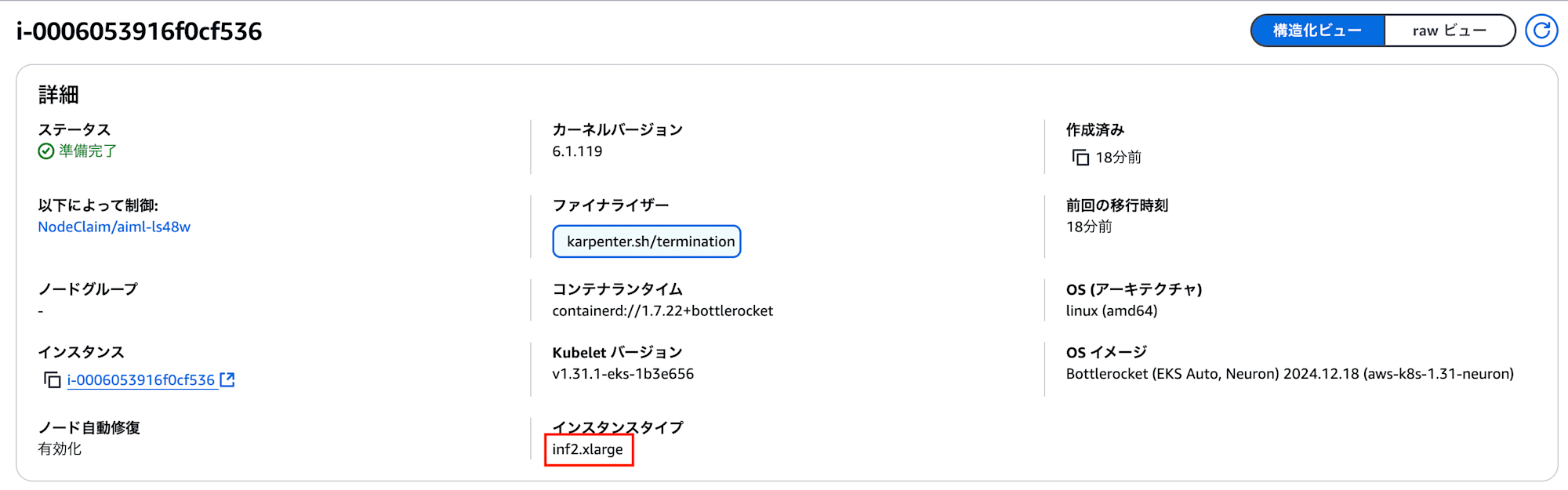
Node: i-0006053916f0cf536/10.0.100.126
Start Time: Wed, 01 Jan 2025 23:54:47 +0900
Labels: role=inference
Annotations: <none>
Status: Running
IP: 10.0.100.48
IPs:
IP: 10.0.100.48
Containers:
inference:
Container ID: containerd://8109ed2ae15c5e4e1945937bbf4487fe225043f71b400473269d42f33e127a9b
Image: 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-inference-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04
Image ID: 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-inference-neuronx@sha256:c9bb1d9e9696846e85486e2ea1ae7e5835c48d0a997c679d57398035a32cbe1e
Port: <none>
Host Port: <none>
Command:
sh
-c
sleep infinity
State: Running
Started: Thu, 02 Jan 2025 00:00:03 +0900
Ready: True
Restart Count: 0
Limits:
aws.amazon.com/neuron: 1
Requests:
aws.amazon.com/neuron: 1
Environment:
AWS_STS_REGIONAL_ENDPOINTS: regional
AWS_DEFAULT_REGION: us-east-1
AWS_REGION: us-east-1
AWS_CONTAINER_CREDENTIALS_FULL_URI: http://169.254.170.23/v1/credentials
AWS_CONTAINER_AUTHORIZATION_TOKEN_FILE: /var/run/secrets/pods.eks.amazonaws.com/serviceaccount/eks-pod-identity-token
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-j9kjz (ro)
/var/run/secrets/pods.eks.amazonaws.com/serviceaccount from eks-pod-identity-token (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
eks-pod-identity-token:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 86400
kube-api-access-j9kjz:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: eks.amazonaws.com/instance-family=inf2
eks.amazonaws.com/instance-size=xlarge
karpenter.sh/nodepool=aiml
Tolerations: aws.amazon.com/neuron:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Nominated 6m18s karpenter Pod should schedule on: nodeclaim/aiml-ls48w
Warning FailedScheduling 5m43s (x7 over 6m19s) default-scheduler no nodes available to schedule pods
Warning FailedScheduling 5m33s default-scheduler 0/1 nodes are available: 1 Insufficient aws.amazon.com/neuron. preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod.
Normal Scheduled 5m23s default-scheduler Successfully assigned aiml/inference to i-0006053916f0cf536
Normal Pulling 5m22s kubelet Pulling image "763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-inference-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04"
Normal Pulled 7s kubelet Successfully pulled image "763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-inference-neuronx:2.1.2-neuronx-py310-sdk2.20.2-ubuntu20.04" in 5m14.725s (5m14.725s including waiting). Image size: 12420172670 bytes.
Normal Created 7s kubelet Created container inference
Normal Started 7s kubelet Started container inference
EKS ノードとして、inf2.xlarge が利用できるようになってますね!
推論用のスクリプトは EKS Workshop のものをそのまま利用します。
先ほどのモデルを利用して、画像認識を行います。
import os
import time
import torch
import torch_neuronx
import json
import numpy as np
from urllib import request
from torchvision import models, transforms, datasets
## Create an image directory containing a small kitten
os.makedirs("./torch_neuron_test/images", exist_ok=True)
request.urlretrieve(
"https://raw.githubusercontent.com/awslabs/mxnet-model-server/master/docs/images/kitten_small.jpg",
"./torch_neuron_test/images/kitten_small.jpg",
)
## Fetch labels to output the top classifications
request.urlretrieve(
"https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json",
"imagenet_class_index.json",
)
idx2label = []
with open("imagenet_class_index.json", "r") as read_file:
class_idx = json.load(read_file)
idx2label = [class_idx[str(k)][1] for k in range(len(class_idx))]
## Import a sample image and normalize it into a tensor
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
eval_dataset = datasets.ImageFolder(
os.path.dirname("./torch_neuron_test/"),
transforms.Compose(
[
transforms.Resize([224, 224]),
transforms.ToTensor(),
normalize,
]
),
)
image, _ = eval_dataset[0]
image = torch.tensor(image.numpy()[np.newaxis, ...])
## Load model
model_neuron = torch.jit.load("resnet50_neuron.pt")
## Predict
results = model_neuron(image)
# Get the top 5 results
top5_idx = results[0].sort()[1][-5:]
# Lookup and print the top 5 labels
top5_labels = [idx2label[idx] for idx in top5_idx]
print("Top 5 labels:\n {}".format(top5_labels))
manifests/modules/aiml/inferentia/inference/inference.py
スクリプトをコンテナ内にコピーします。
kubectl -n aiml cp ./inference.py inference:/
boto3 をアップグレードします。
kubectl -n aiml exec inference -- pip install --upgrade boto3 botocore
先ほど S3 バケットにアップロードしたモデルをダウンロードします。
kubectl -n aiml exec inference -- aws s3 cp s3://masukawa-eks-gpu-output-bucket/resnet50_neuron.pt ./
推論します。
kubectl -n aiml exec inference -- python /inference.py
Top 5 labels:
['Persian_cat', 'lynx', 'tiger_cat', 'Egyptian_cat', 'tabby']
推論に使ったのは下記子猫の画像です。

猫種がわからないので答えがわからないですね...笑
lynx(オオヤマネコ)、tabby(トラネコ)含めて全部猫を提示してきているので推論はできていそうです。
まとめ
今回は EKS Auto Mode で Trainium と Inferentia を扱ってみました。
GPU インスタンス(Neauron インスタンス)はドライバのインストール等手間がかかるイメージがありましたが、拍子抜けするくらい簡単でした!
EKS Auto Mode では複数種類のインスタンスを組み合わせて利用しやすいため、CPU と GPU を組み合わせて使うワークロードだとよりメリットが大きい気がします。









